

You would hear a lot about the three V’s of data – Volume, Variety & Velocity. Every enterprise and almost any application of enterprise grade is facing growth in consumption and therefore, growth in the data it consumes, generates, processes & stores as well as the forms of the data that’s been processed.
While in the data analytics paradigm, technology has evolved to cater to this, existing IT systems also have to scale to cope with this higher volume of data and the velocity at which data needs to be processed. Scaling application workloads has always had various solutions from spinning up multiple instances, managing them in a cluster, implement sticky session or session replication to implementing service lines and mirrors. More recently, horizontal scaling has become a norm to adopt to changing consumption patterns, supported by evolution of containers & container orchestration platforms. Managing scale ability of databases, however, isn’t as straight forward and is not very well understood by a large section. And this has been a culprit for a lot of application outages we have come across when we have been called upon to help teams stabilize their production environments. For most part, even though there is sufficient monitoring infrastructure in place and teams are aware of the possibility of an upcoming hazard, they just aren’t sure on how to respond sometimes.
In this post, I am talking about thinking behind some of the common design options to scale up databases and when to think about these options. I classify these two ways based on typical needs – to meet the increased transaction volumes and to meet the increased data volume.
Increasing transaction volumes
One of the simplest solution to scaling your database to cater to increased volume of transactions is scaling vertically i.e. increasing the processing capacity by adding more compute and memory of the host machine. This is a simple solution and you should think about this when you experience CPU or memory exhaustion on database server while your disk utilization and IOPS is acceptable. It comes with many limitations though. There is a physical limit to how far you can scale vertically – both in terms of the amount of resources you can add & in terms of whether they will effectively add capacity to process more transactions. The hardware required to grow vertically will also be high-end relatively to allow for addition of more compute & memory as needed. Additionally, you may also run into trouble with the storage IO limit as the storage controller is still the same.
You could get around this issue with vertical scaling by spanning more processes on the same machine. Unless you can split your database into multiple entirely separate databases and run them on separate server instances, you could possibly do it in two different ways –
- Load balancing transactions between the processes
- Split load of different types of transactions between the processes
The first one refers to clustering where a cluster of nodes caters to the transactions. This requires a multidirectional synching mechanisms to ensure all transactions that change state of the data are synchronized across all the instances of the cluster. This is a good way to go when you have a largely read-oriented traffic and data integrity isn’t critical e.g. you are not running a financial system etc.
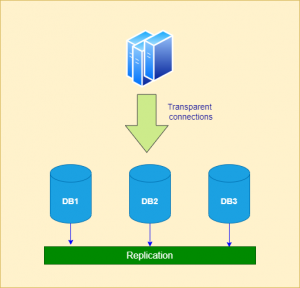
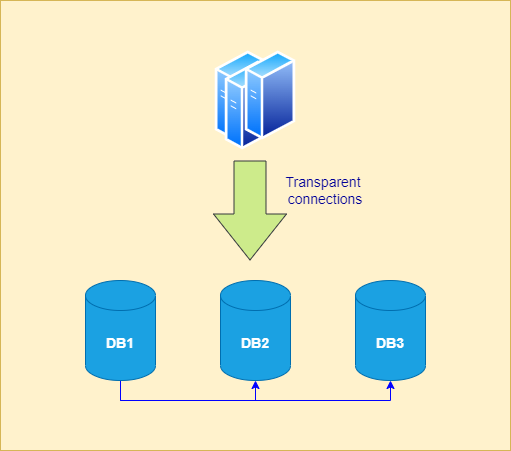
A risk that comes with clustering is data conflicts where state of the same data was modified on two different instances in the cluster at the same time. Because of the multidirectional nature of the synchronization, a true state of the data may be overwritten, lost or corrupted. Data integrity is key to any data management solution therefore, cannot be compromised in most cases. To prevent such scenarios from happening, a cluster pattern frequently utilized is master-slave where one of the nodes in the cluster is made responsible for maintaining the true-state of the data and other nodes only cater to transactions which only require reading the data therefore, being termed as read-replicas. This is often associated with a cloud-native architecture pattern named CQRS too. This is also a good solution to think about when you want to separate reporting workload to a read replica and have master cater to the online transactions.
 Currency vs Performance
Currency vs Performance
A key design decision for both these designs involves trading off between the tolerance for old state of data being returned from one of the nodes in the cluster vs the time it takes to complete a transaction. If data currency is critical i.e. the tolerance for data inaccuracy is low, you will need to design the solution to consider transactions committed only after they have been synchronized to all nodes. On the other hand, if performance of committing a transaction is critical, some amount of tolerance will need to be there in the currency of data.
Scale for data volume
While a increased data volume can be associated to an increased transaction volume, it is not always the case. Depending on what kind of system it is, how long does the transactional data need to be retained in the live environment and what are the various policies & constraints around archiving & purging, some systems, in spite of catering to a multitude of transaction volumes can continue to contain the data volume within certain boundaries that they are able to deal with without having to compromise on performance, data integrity or operational challenges of any kind.
When data volume does increase along with or without increase in transaction volume, it leads to poorer performance of transactions as well as higher utilization of resources to be able to execute the transactions. This usually happen when one or some of the tables which stores the transactions blow up and not much dependent on the overall size of database. Why does this happen? You may be aware databases rely on indexes to find data in a table. These indexes may be defined by you or your team during design or may automatically be created by the database system based on the data type. With increase in data volume, the efficiency of searching through the index is lost. Moreover, the efficiency of carrying out a transaction also goes down because of having to update a bigger index.
To counter this, databases provide a mechanism called Table Partitioning which allows you to specify one of the fields as a partition key using which database stores the transactions into separate segment as individual tables therefore, reducing the data size for each of those tables and maintain efficiency of reading & writing data. The partition key needs to be carefully chosen and should be a field which should occur in most reads and writes as a criteria i.e. in one of the WHERE clauses of the query. This allows the database to identify from the query itself which partition to target for the query therefore, providing the efficiency. If this isn’t taken care of, the database ends up querying all the partitions taking away any advantages of partitioning. Partition also allows the most efficient method of archiving and purging data. Think about this when your main transactional tables start to grow, perform starts to get impacted and there isn’t any more scope for tuning the queries and indexing.
The limitation around partitioning being only effective when the partition key is involved along with it being a table-level mechanism does limit its use cases. There are scenarios where the volume of data across tables is growing at high velocity. Choosing partition keys for all such tables to suit the requirements of all the various combination of transactions may not be viable. Or the data volume growth may be exponential. Most of all, partitioning is still within the same database instance and if the transaction volume is high, which is likely with high data volume, the scaling limits of a single database surface again.
Database distribution & routing
In certain large scale cases, partitioning is taken to another level where systems are dealing with terra bytes of transactional and master data combined within a OLTP system, an even more sophisticated solution comprising of multiple databases with identical data model but separate segment of data is implemented. This also requires the use of a dictionary or catalogue to keep routing information for application or mediator to refer to to route transactions to the right instance. An example of this is large banking systems which may choose to segregate their customers and all of their account data into separate databases.
This is quite a niche use case and with modern techniques like sharding around, this doesn’t get implemented as much because of the involved overhead at various levels. This introduces a potential single point of failure and congestion in form of the routing dictionary.
Sharding
A solution that takes data distribution to another level is sharding. This brings the benefits of partitioning and clustering baked into one wherein partitions are spread across multiple instances of the database. This really eliminates the scaling limitations of a single database which stills simplifying life around managing database distribution & routing by taking it over completely. The currency & performance tradeoff still stays however, most database products supporting sharding also allow you to implement ACID or Eventual Consistency policies. Sharding has also bee one of the key factors in the widespread adoption of non-relational database who had the opportunity to learn from the failures of relational database and address it along side other things.
Hope this provided you some low down on the thinking behind various data scaling mechanisms and when to utilize them.
Written by:
Anurag Setia






